Our Capabilities
Current technologies provide opportunities to make more informed decisions by leveraging the vast amounts of data available today. Our capabilities across the full data lifecycle enable our clients to find answers to the growing number of complex problems they are chartered to address.
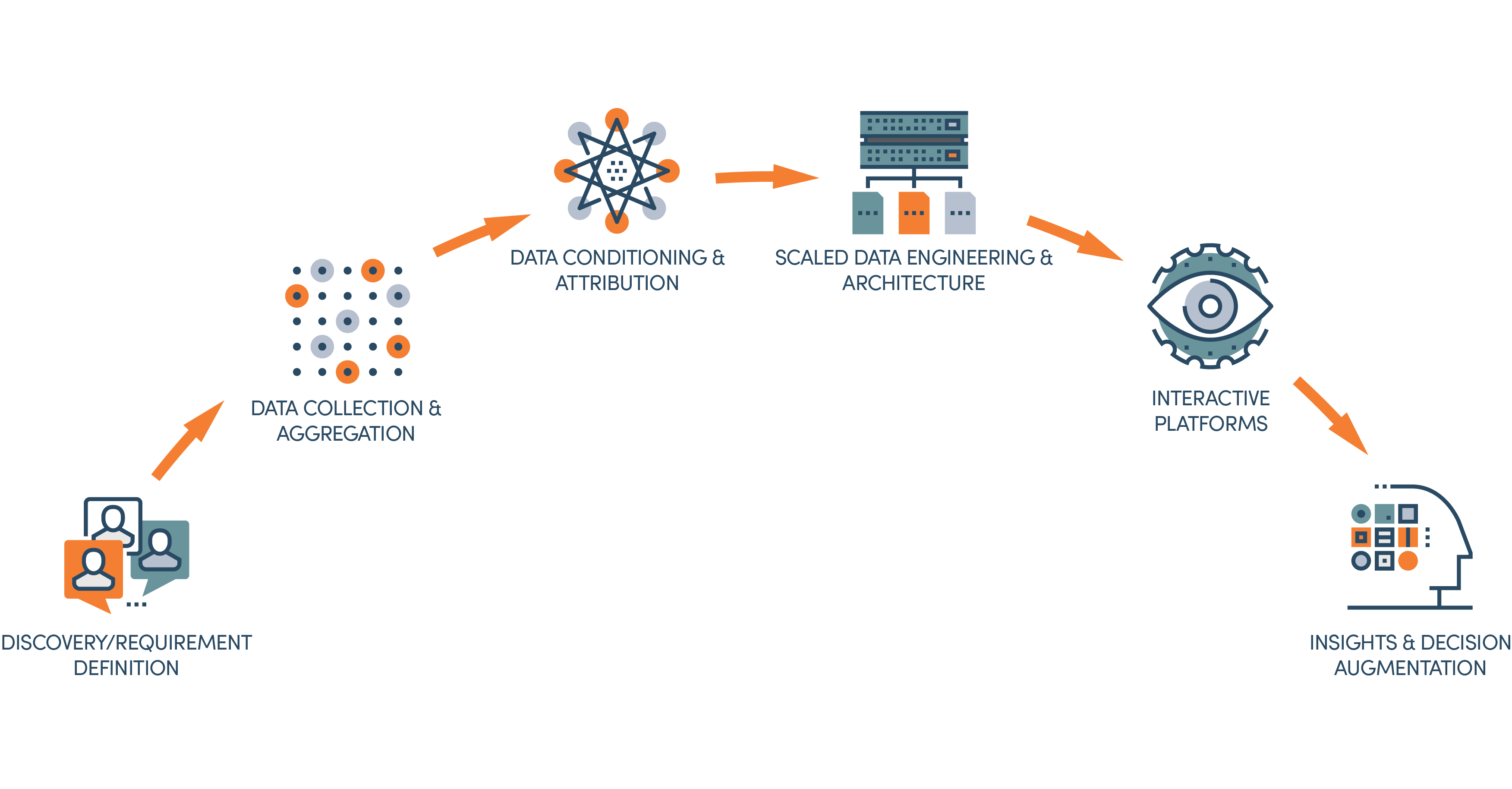
Discovery / Requirement Definition
Each of our clients’ challenges is unique, so we take the time to clearly understand those challenges and identify the right tailored solution(s). Our team of project consultants engages directly with our clients’ business and technology teams to define their needs as well as the value and objectives of their desired solution.
This includes evaluating the current client environment, considering data sources and stores, available APIs, computational/data processing utilities, and UI/IX environments. Then, leveraging Intrics’ proven process, we develop a customized solution path and the related technical requirements, costs, and timelines.

Data Collection & Aggregation
At the root of any intelligence solution is raw data. That can include data provided by our client (such as cost, volume, t-log, etc.) or newly collected competitive data from our partner company RetailData.
Intrics can accurately and reliably capture and report on any observable data point across the entirety of the internet, as well as in any physical location in North America.
Intrics’ team of web extraction engineers have established an expansive knowledge of the many nuances related to web auditing. In addition, highly skilled field associates complete in-store collections, providing coverage across all of North America.
Using proprietary mobile data collection applications, Intrics can create a highly custom data collection program to capture prices, evaluate merchandising, conduct compliance checks, capture images and any other observable factor that can be converted into data.

Data Conditioning & Attribution
Data conditioning is a key step that addresses the old adage of “garbage in, garbage out.” Leveraging various data science techniques including regression models, rule engines, machine learning algorithms and various human in-the-loop utilities we diligently condition source data to the standard needed for downstream operations. Inadequate focus is often applied to data conditioning efforts, which can lead to unreliable intelligence being used to make critical business decisions.
We consciously avoid the common pitfall of applying an outliner truncation methodology to data conditioning. If outliers are consistently cut off, shifts in behavior can be missed and therefore no response will be formulated, degrading brand image and potentially contributing to defection of customers. Instead, we seek to leverage multifactor engines to probabilistically represent highly accurate source data signals, allowing the truest representation of behaviors/patterns identified within the data.
Data attribution maximizes the value derived from data and is critical in developing scaled decision systems. This includes featuring engineering of defined aggregations, calculations, measures, conversion factors, and parameters to be leveraged by the data engineering team. In this step, we also partner with our clients to leverage their unique libraries in conjunction with our own proprietary libraries to ensure all fields such as size, pack, and UOM are consistently populated and/or synonyms are defined. Depending on the needs of the project, we complete relational mapping that utilizes data science techniques including elastic, python, and automated classification tools. These solutions provide common keys across otherwise disparate data sets, allowing comparison and patterning that would be infeasible otherwise.
For example, unifying categorization schema of multiple competitors to a client specific hierarchy or grouping, unifying codes such as UPC, SKUs or similar product identifiers to common client specific definition, allowing for comparison that wouldn’t be possible given the inconsistency of product identifiers across the industry. The ability to efficiently map disparate data sources is critical as UPCs have become less relevant in retail, private labels expand, and brands look to diversify their assortments.

Scaled Data Engineering & Architecture
Data engineering is the core element to any successful intelligence or decision platform. Basic Excel and BI solutions could wrangle hundreds of thousands of records, but now that most businesses are facing hundreds of millions to billions of records, a stronger and more sophisticated solution is required.
Developing sophisticated dynamic software platforms is not entirely dissimilar to building architects and engineers designing remarkable structures while safely managing loads—solutions must be robust but elegant.
As businesses seek to leverage an ever-increasing amount of data for decision making, proactively designing your data fabric and interim model layers between source data and final user interaction platforms is paramount to capturing the most value.
As our partner company RetailData’s volumes transitioned from processing millions to many billions of weekly data points to support client needs, we established an expertise in the most advanced cloud-based technologies for data storage, modeling, and processing. This includes SQL and NoSQL solutions, BLOB and warehouse storage, and dynamic scaling algorithm development to optimize computational cost and user responsiveness, along with analytics services and data marts to support interim modeling between raw data and the final user interaction layer of a solution.

Interactive Platforms
Intrics leverages the most modern development languages, techniques, and libraries to develop intuitive and actionable platforms. Our team of program consultants, architects, full stack developers, and visualization engineers collaborate with business users to define and deliver application requirements. These can include security protocols, front-end state model definitions, UI/UX environments, defined API protocols, personalized rules-based alerts/notifications, and back-end data movement methodologies to meet your application needs.

Insights & Decision Augmentation
A deep, nuanced understanding of a situation is vital in empowering a good decision. Thus, insights are at the center of any intelligence solution. In partnership with our clients, our retail intelligence team efficiently synthesizes the three pillars of an insight: (1) quality and confidence in the underlaying data, (2) applied analytics, and (3) contextualized interpretation of trends and patterns.
This approach leverages our vast domain knowledge across retail to deliver actionable insights our clients can use to improve competitive positioning, category performance, customer loyalty and value, and operational proficiency.
